写在开头
图片的问题暂时还没有解决,主要是我没有备案的域名啊,而且对我来说也没有什么必要的,我正在想办法把图片转移到阿里云OSS上,还需要一点时间……emmmm我们多贴一点代码,代码才是王道!
今天我们说一下Java编程的很重要的一部分:Java集合.
集合
为什么要引入集合
举个栗子
要求1: 存储3个学生的信息(姓名,年龄),能够将3个学生的信息展示出来
数组: 存储基本数据类型 int[] i = new int[3]; String[] s = new String[3];
要求2: 除了三个学生之外,后还要添加一个学生
原数组做不到!
原因是因为数组,是一个定长的容器,定义时给定长度,容量就不能改变
集合: 集合也是一个容器,承装一些数据,有一些集合的底层也是通过数组的方法来进行数据的存储. 但是,如果数据增加,集合底层在没有地方存储数据时,再为你开辟一个更大的空间用于存储数据,因此集合相对于数组来说,容量可变
代码:
1 | package io.cnfox.collectiont; |
1 | package io.cnfox.collectiont; |
两者的相同与不同
相同点
- 两者都是作为一个容器来进行数据的存储.
不同点
数组定长,定义时必须给定一个长度,而且已经定义容器的大小就不能改变.
数组不定长,定义是不必给定一个长度,是一个长度可变的容器.
数组可以存储基本数据类型,也可以存储引用数据类型.
int [] i = new int[3]
集合只能存储引用数据类型,如果想存储基本数据类型,需要进行Zion给装箱拆箱操作,将基本数据类型自动装箱,编程对应的应用数据类型,用数据包装类,存储在集合中.
数组使用简单,方法继承自Object类中,属性求取数组的长度 length.
数组中集合了很多方法,不仅仅继承自Object类中 还封装了很多自己的方法.
如果数据内容固定,一般使用数组.
如果要进行容器的增删改查操作,使用集合进行操作会相对简便.
Collection接口
框架集合分类图
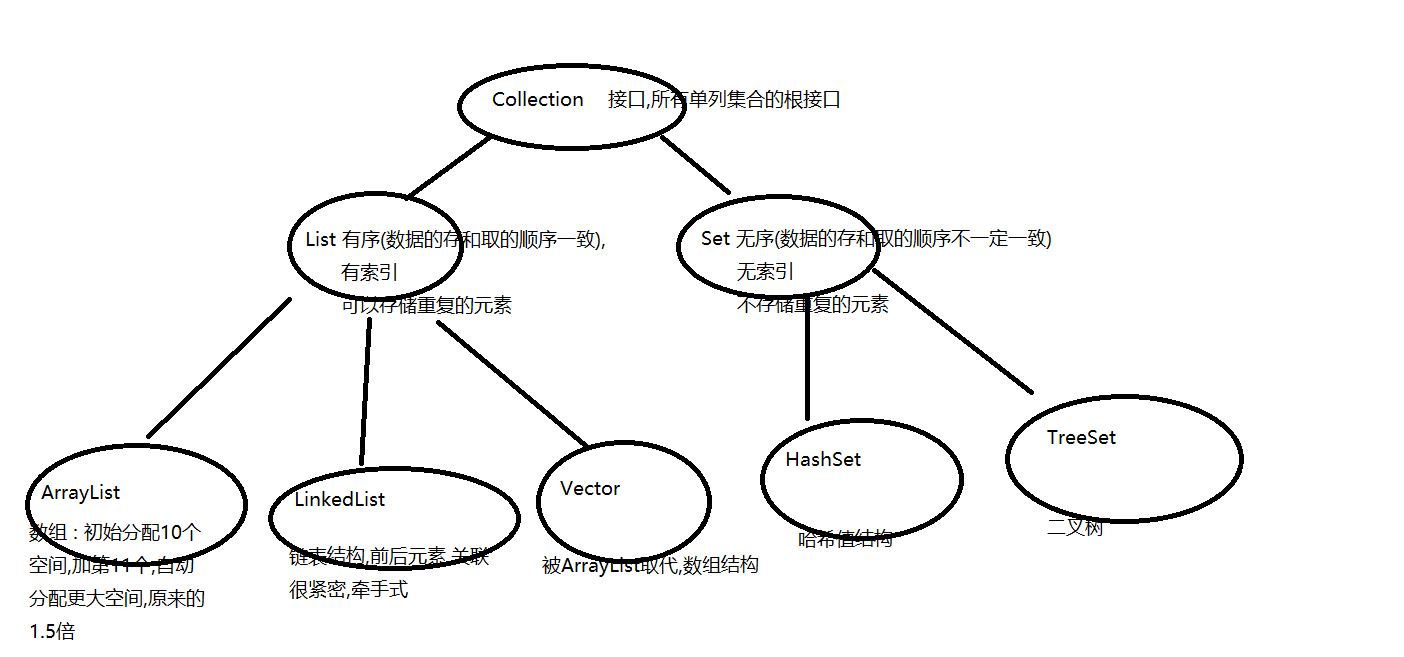
Collection 接口的常用方法
Collection : 接口,java.util.Collection,需要找到一个实现类,要求实现类中将接口的所有抽象方法都重写了一遍
最常用的ArrayList java.util.ArrayList
定义方式: Collection c = new ArrayList(); // 接口的多态
方法:
- add(Object obj): 向集合中添加元素,默认添加在集合的末尾位置,返回值类型为boolean,如果项集合中添加元素成功,返回true,添加元素失败,返回false
- remove(Object obj): 将集合中的某一个元素删除掉
将集合中的某个元素进行删除,删除成功返回值为true,没有删除成功,返回false - clear() : 将集合进行清空,将里面的所有元素,全部删除,但是集合仍然存在的,没有返回值
- isEmpty() : 判断集合中是否有数据,没有数据,返回值为true,有数据,返回false
isEmpty() : 使用场景,如果要针对集合进行遍历, 1. 先判断集合 != null 2. 集合中有数据遍历才有意义 - size() : 获取到集合中数据的个数,返回值int类型
- contains(Object obj): 判断集合中是否包含某一个元素obj,包含,返回true,不包含,返回false
1 | import java.util.ArrayList; |
1 | import java.util.ArrayList; |
其他ALL方法:
- addAll(Collection c): 表示将一个集合c添加到另外一个集合的末尾,添加成功返回true,
- removeAll(Collection c): 表示将集合c中在集合a(谁调用removeAll,a就代表谁)中重复元素进行移除(取a和c;两个集合的交集,在a中进行删除)
- containsAll(Collection c) : 判断c集合是否完全包含在调用方法的集合中,完全包含返回true,不完全包含返回false
- retainAll(Collection c): 获取两个集合的交集,将交集赋值给方法调用的集合,如果方法调用的集合内容改变,返回true,没改变,返回false
1 | import java.util.ArrayList; |
注意事项:
1 | import java.util.ArrayList; |
Collection 集合的遍历方式
将集合中的元素,一个一个获取到
toArray() : 返回一个包含此集合中所有元素的数组。返回值Object[]
1 | package com.zgjy.demo1; |
迭代器
迭代器: 迭代,就指,将一个容器中数据一个一个的拿出来(可以理解成循环,遍历)
iterator()方法 : 获取集合的迭代器对象,返回值类型Iterator,
Iterator是一个接口,来自java.util.Iterator
Iterator it = new Iterator (); // 接口,不能实例化对象的,这个表达式不会出现
Iterator it = new 实现类();// 正确方式
Iterator 接口中的方法
hasNext() : 判断集合中是否有下一个元素,如果有,返回值为true,如果没有,返回值就是false
使用场景: 一般用于判断集合中是否有下一个元素,以此来确定是否要接着进行集合的遍历
next() : 获取集合中的元素,返回值类型可以理解成Object
说明:
迭代器在使用中比较推荐: 为什么? 原因是,
- 迭代器可以进行所有容器的遍历(数组和集合)
- 迭代器遍历的时候,不看索引,只看容器中有没有下一个元素
1 | import java.util.ArrayList; |
迭代器原理和注意事项
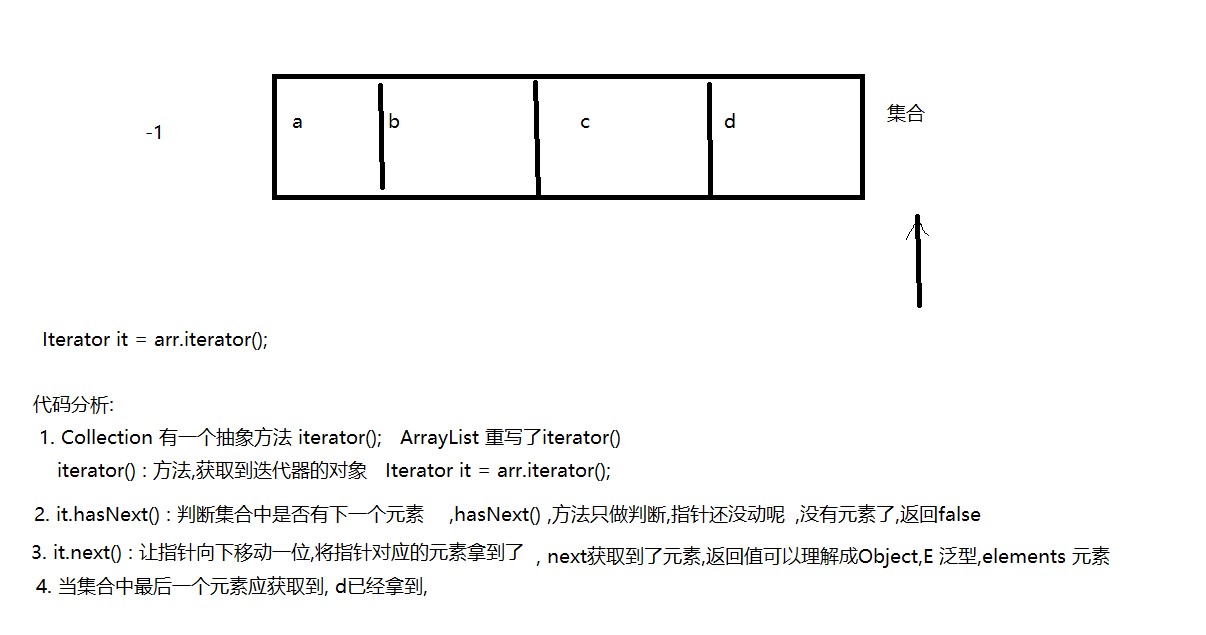
注意事项:
- hasNext() : 方法只做集合中是否有下一个元素的判断
- next() : 将指针向下移动一位, 获取到指针对应的元素
集合中没有元素,还通过next()获取,报出 : java.util.NoSuchElementException
迭代器并发修改异常
异常发生的原因: 在使用迭代器进行容器的遍历时,同时还对这个容器中的内容进行了修改(增加,删除),这个时候,报出异常: java.util.ConcurrentModificationException 并发修改异常
上述的情况如何解决:
listIterator(): 方法来自于ArrayList 类中,将集合的迭代器获取到,返回值类型ListIterator,来自java.util.ListIterator
ListIterator用于允许程序员沿任一方向遍历列表的列表的迭代器,在迭代期间修改列表,并获取列表中迭代器的当前位置(解决了Iterator迭代时,不能修改集合的问题)。
ListIterator : 是一个接口,不能实例化对象,依靠实现类,listIterator() 方法的返回值实际上是ListIterator 接口的一个实现类对象
1 | import java.util.ArrayList; |
List接口
List : 来自于 java.util.List 接口,不能实例化对象,依靠实现类,ArrayList
List中的特有方法:
- add(int index, E element) : index表示索引, element元素,将element添加到集合的指定索引位置上
- remove(int index) : index表示索引,将集合中指定索引位置的元素删除掉,返回之类类型E,理解为Object
- get(int index): 获取指定索引上的元素,常用,原因,可以做集合的遍历,List集合有索引
- set(int index,Object elements): 将指定索引上的元素替换成elements
1 |
|
ArrayList,LinkedList,Vector
区别
底层的数据结构不同
ArrayList : 底层使用数组实现的
LinkedList: 底层是链表结构(节点结构)
Vector : 底层数组结构,目前已经被ArrayList取代了使用性能不同
ArrayList : 查询快,增删慢
LinkedList : 查询慢,增删快
Vector: 都慢,线程安全数据结构图解
ArrayList的存储方式
LinkedList: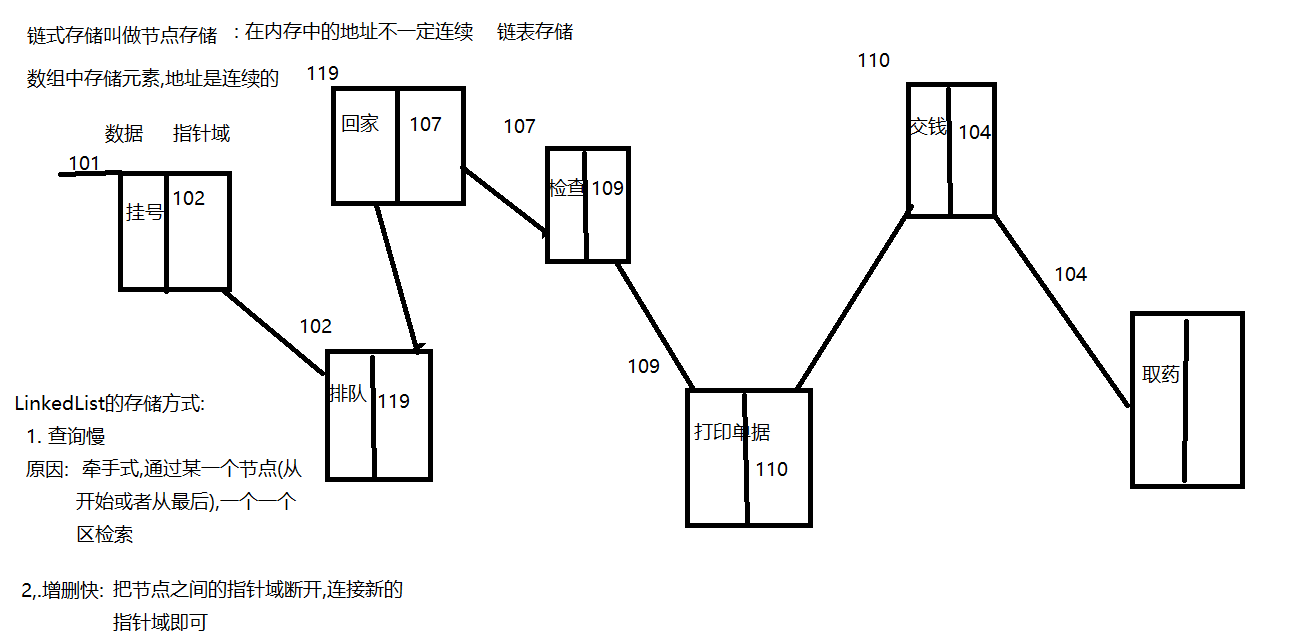
LinkedList特殊方法
- addFirst(E e): 向集合的开头添加一个元素
- addLast(E e) : 向结合的末尾添加一个元素
- getFirst() : 获取集合中的第一个元素
- getlast() : 获取集合中的最后一个元素
- removeFirst() : 删除集合中的第一个元素
- removeLast() : 删除集合中的最后一个元素
1 |
|
Vector
1 |
|
泛型
泛型: 广泛的类型,JDK中很多的方法,返回值类型Object,通常需要转型
如果有一个类,里面有方法,这个方法定义时,返回时,针对于需要的类型并不确定,就可以在类上或者方法上使用泛型举例: Collection
, E就表示是泛型,可以理解成Object类型,原因是Collection作为集合,是一个容器,容器中就可以存储多种数据类型,不限定数据类型,接口上面加了一个泛型,证明各种对象类型,都可以存储 泛型的定义方式: <泛型类型>
泛型好处:
- 提高代码的安全性,能将运行环节的问题,提前暴露,编译环节
- 不需要强制类型转换
- 日后使用集合的时候,加上泛型
没有添加泛型的代码:
1 |
|
加了泛型的代码
1 |
|
泛型定义的注意事项
泛型添加时,前后的类型需要保持一致
举例: ArrayListal = new ArrayList (); 在JDK1.7版本之后,定义集合的时候,后面的泛型可以省略,根据前面定义的泛型为准
// 前面有泛型,后面泛型可以省略
ArrayListarrayList = new ArrayList<>(); 泛型定义的书写规范: <泛型>
ArrayList
泛型可以使用英文字母进行表示: E ,T ,K,V, Q,W, 一般来说,泛型没有指定的必须规则,但是通常是一个大写字母表示1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import java.util.ArrayList;
public class FanXingDemo2 {
public static void main(String[] args) {
// int[] arr = new String[3]; 错误的
// ArrayList<String> arrayList = new ArrayList<Integer>(); 错误代码,前后泛型保持一致
// ArrayList<Object> arrayList = new ArrayList<Integer>(); 错误代码,前后泛型保持一致
// 前面有泛型,后面泛型可以省略
ArrayList<String> arrayList = new ArrayList<>();
}
}
带有泛型的类
说明:
- 类在定义的时候,进行泛型的书写规范
- 类上声明的泛型,可以当做一个普通成员变量,在类中使用
- 在进行类的实例化对象时,可以给泛型进行类型的确定
1 |
|
1 |
|
带有泛型的方法
格式有点复杂 我放在代码块里了
1 | 1. 普通方法: |
1 |
|
1 |
|
1 |
|
带有泛型的接口
说明:
接口上带泛型,实现类的实现方式有两种
- 实现类上不带泛型,要求实现的接口上,必须要给定泛型,推荐使用
- 实现类上带泛型,不需要指定接口上的泛型类型
1 |
|
Set集合
概述:
Interface Set
List集合和Set集合的特点:
List集合特点 :
- 有序(数据的存储和取出顺序一致)
- 有索引
- 可以存储重复元素
Set集合特点:
- 无序(数据的存储和取出不一定一致)
- 没有索引
- set不存储重复元素
方法
1 |
|
Set集合的遍历
- toArray() : 方法,先将set集合中的所有数据封装到有个object[]中,再进行object[]的遍历
- toArray(T[] t): 方法,定义一个数组,toArray中的参数,是一个数组,带有泛型的数组,参数中数组的泛型与要遍历的集合中的泛型保持一致;表示将数组封装到t所表示的数组中,因此t类型的数组在定义时,长度要大于等于集合的长度,以便盛装数据
- iterator() : 迭代器遍历
1 |
|
增强for循环
增强for : forEach, 也是一种循环,通过获取集合或者数组中的元素,来进行循环的
增强for底层其实也是通过迭代器的原理来实现的,使用起来更加简单,增强for获取元素不通过索引,所以适用性也很强
语法格式:
for(元素数据类型 变量名 : 集合或者数组 ){
}
说明:
- : 是英文的冒号
- 集合或者数组 : 表示要进行遍历的容器
- 元素数据类型: 需要与容器中的数据类型保持一致
- 变量名: 表示每次循环获取到的元素名称,但是每次遍历的过程中,变量名所代表的元素内容不一样
- 为什么forEach使用简单: 因为直接将容器中的元素拿到了
1 |
|
Set集合保证数据的唯一性
JDK中的类,基本上都重写了hashCode和equals 方法,因此可以直接使用,就保证了元素的去重复特性
1 |
|
定义类型通过set集合保证元素唯一性
Set通过什么方式来保证元素唯一, HsahSet 底层哈希表的结构(数组+链表)
比较不同的元素是否是相等的
hashCode : 哈希值,Object中的方法hashCode(),功能: 不同的对象,返回不一样的十进制数
equals: 比较,Object中方法,功能: 比较两个对象的地址是否一致,重写了equals方法之后,比较的是对象里面的成员内容
1 |
|
1 |
|

Map集合
Map : 英文地图,也是一个容器
Interface Map<K,V> : Map是一个接口,双列集合的根接口
Map<K,V> : 两个泛型,K,V,两列, key 键 value 值,Map通过一个数据(key)找到另外一个数据(value), key与value之间的关系,称为映射关系,1对1的关系,一个key对应一个value
Map集合中特点:
key是唯一的,value不是唯一的,key在map集合中,不重复,value是可以重复的
Map中的key值,保持元素不重复的原理,与HashSet一样的
HashMap 哈希表
常用方法
Map是一个接口,依靠实现类进行功能的实现,HashMap
Map<K,V> map = new HashMap();
- put(K key,V value) : 向map集合中添加键值对的映射关系
说明: 1)如果key在map中不重复,直接添加键值对成功2) 添加的key在map集合中已经存在,后面的key对应的值替换掉前面key的值
1 |
|
- size() : 求map集合中元素个数是多少,返回值为int类型
- clear() : 清空map中的数据,数据没有了,map集合仍然存在,返回值为void
- get(Object key): 通过map中的key值,获取到对应的value值,返回值类型为value值类型
1) key存在于map中,获取到对应的value值
2) key不存在于map中,得到的结果就是null - containsKey(Object key) : 判断map集合中是否包含给定的key值,包含返回true,不包含返回false,返回值boolean类型
- containsValue(Object value) : 判断map集合中是否包含给定的value值,包含返回true,不包含返回false,返回值boolean类型
1 |
|
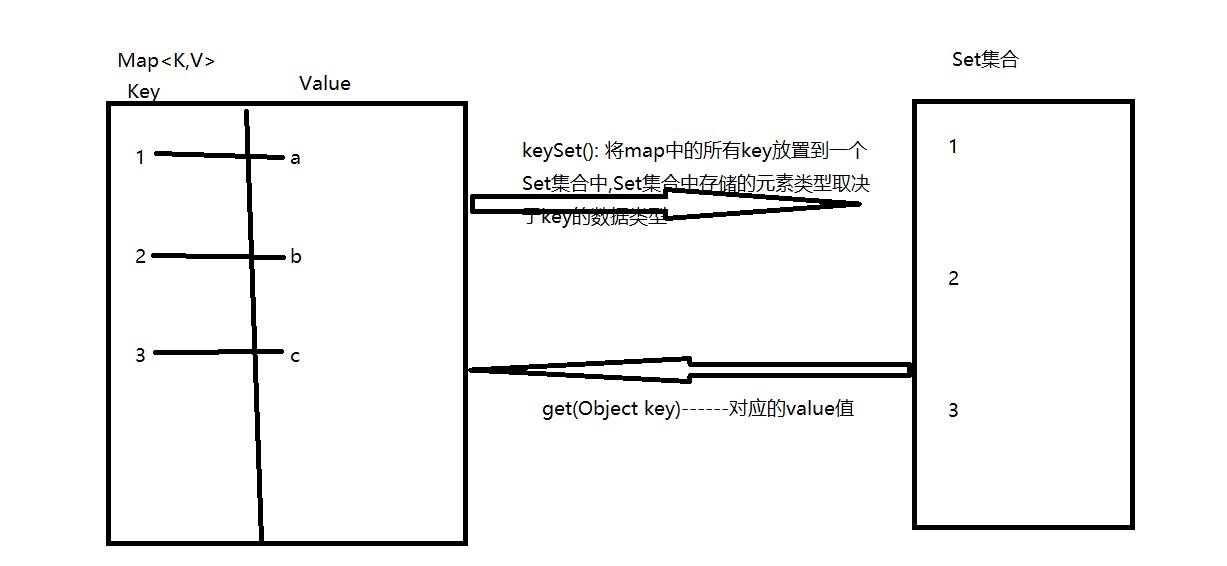
Map集合的两种遍历方式 ⭐ ⭐
- keySet() : 方法,来自实现类HashMap,表示,将Map集合中所有的key的值获取到,将key的值封装到一个set集合中,返回值结果,Set<泛型>,返回的Set集合中的泛型类型与Map中的key值的类型保持一致
1 |
|
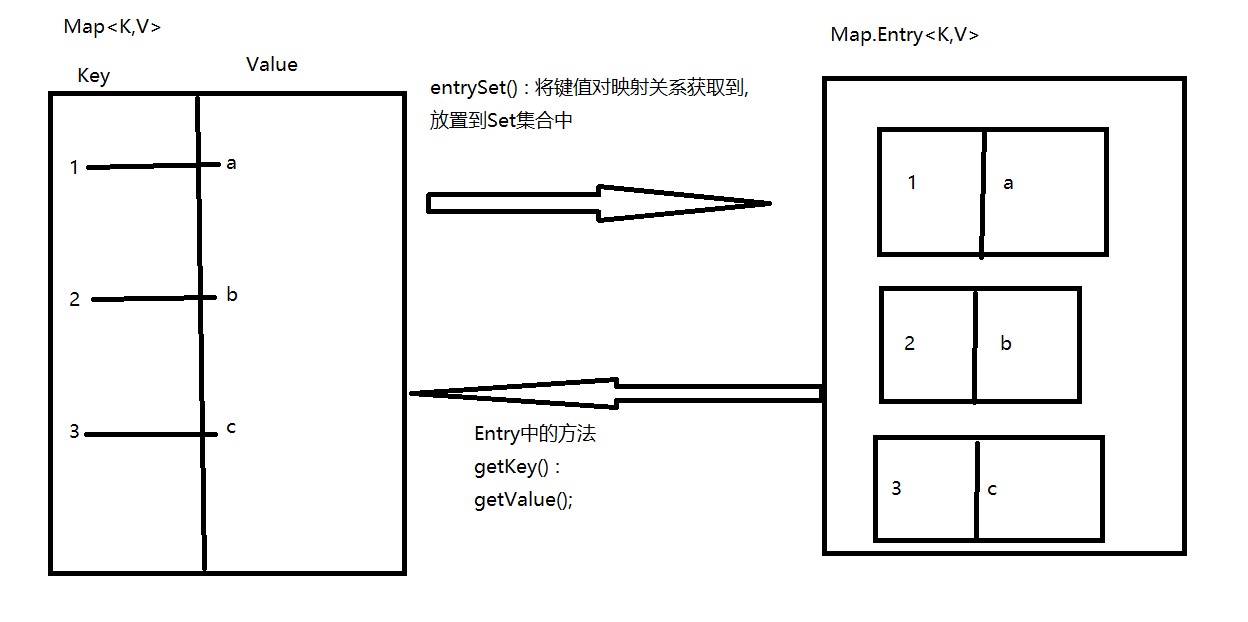
entrySet(): 表示将Map集合中的键值对映射关系获取到,返回值类型
Set<Map.Entry<K,V>>
Map.Entry<K,V> : Entry是接口,定义在Map这个接口的内部,Entry表示入口,
Entry<K,V>,就叫做键值对的映射关系
获取到了Entry<K,V>映射关系后,通过Entry中的方法
getkey() : 获取到映射关系中key值
getValue() : 获取到映射关系中的value值
1 |
|
Map集合中将自定义类型作为key值
1 | Map接口,依靠实现类HashMap |
1 |
|
1 |
|
练习
键盘录入一个字符串,统计每个字符出现的次数
例如,录入aaaabbccddd!@#@#$@#$%cc66ff
打印出来:a有4个,b有2个,c有4个,d有3个,!有1个,@有3个,$有2个,%有1个,6有2个,f有2个
1 |
|
HashMap的子类 LikeedHashMap
LinkedHashMap : 是HashMap的一个子类,功能与HashMap基本一致,特点就是,能够使得通过LinkedHashMap 存储的数据,取出的顺序保持一致
HashSet : 也有一个子类LinkedHashSet, 功能上与hashSet基本一致,能保证,元素的存和取的顺序一致
1 | import java.util.HashMap; |
hashmap和hashtable的区别 ⭐ 面试
Hashtable 也是用于存储键值对的映射关系,使用的相对少了
区别:
版本区别:
Hashtable JDK1.0版本
HashMap JDK1.2版本
存储数据区别:
Hashtable 键值都不能存储null类型,报错
HashMap 键值可以存储null类型
线程安全的区别:
Hashtable 线程安全,运行慢
HashMap 线程不安全,运行快
1 |
|
Collection 工具类
Arrays : 对于数组的工具类
Collections : 对于集合的工具类,List集合,里面的方法都是静态方法,可以类名.直接使用
- binarySearch(List
list ,T key) : 表示将key值在集合中的索引位置返回.
1) 集合中没有这个元素,返回值是一个负数
2) 存在这个元素,返回元素在集合中的索引值 - max(Collection c): 将集合中的最大元素进行返回
- min(Collection c): 将集合中的最小元素进行返回
- shuffle(List list) :将集合中的内容进行混乱排序
- sort(List list) : 对集合中的数据进行排序,默认升序排列(从小到大)
1 |
|
斗地主案例
按照斗地主的规则,完成洗牌发牌的动作。
具体规则:
1. 组装54张扑克牌
- 将54张牌顺序打乱
- 三个玩家参与游戏,三人交替摸牌,每人17张牌,最后三张留作底牌。
- 查看三人各自手中的牌(按照牌的大小排序)、底牌
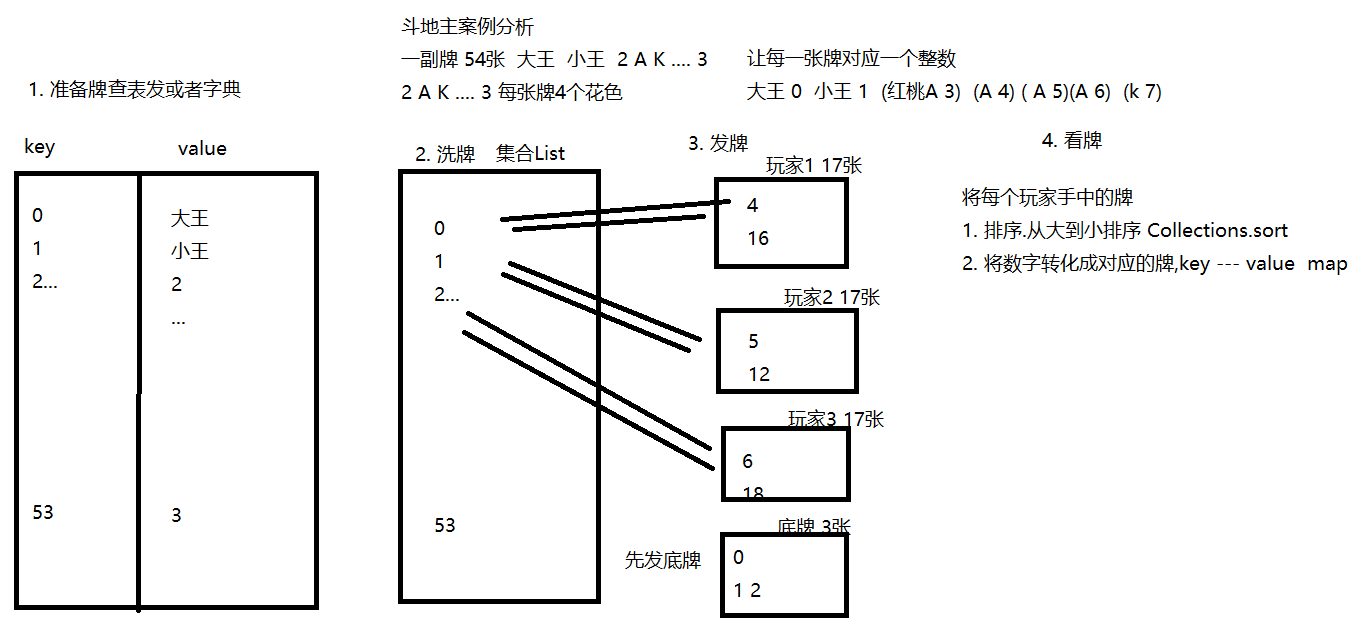
手中扑克牌从大到小的摆放顺序:大王,小王,2,A,K,Q,J,10,9,8,7,6,5,4,3
1 |
|
晚安
今天就到这里了,明天见,加油!

